
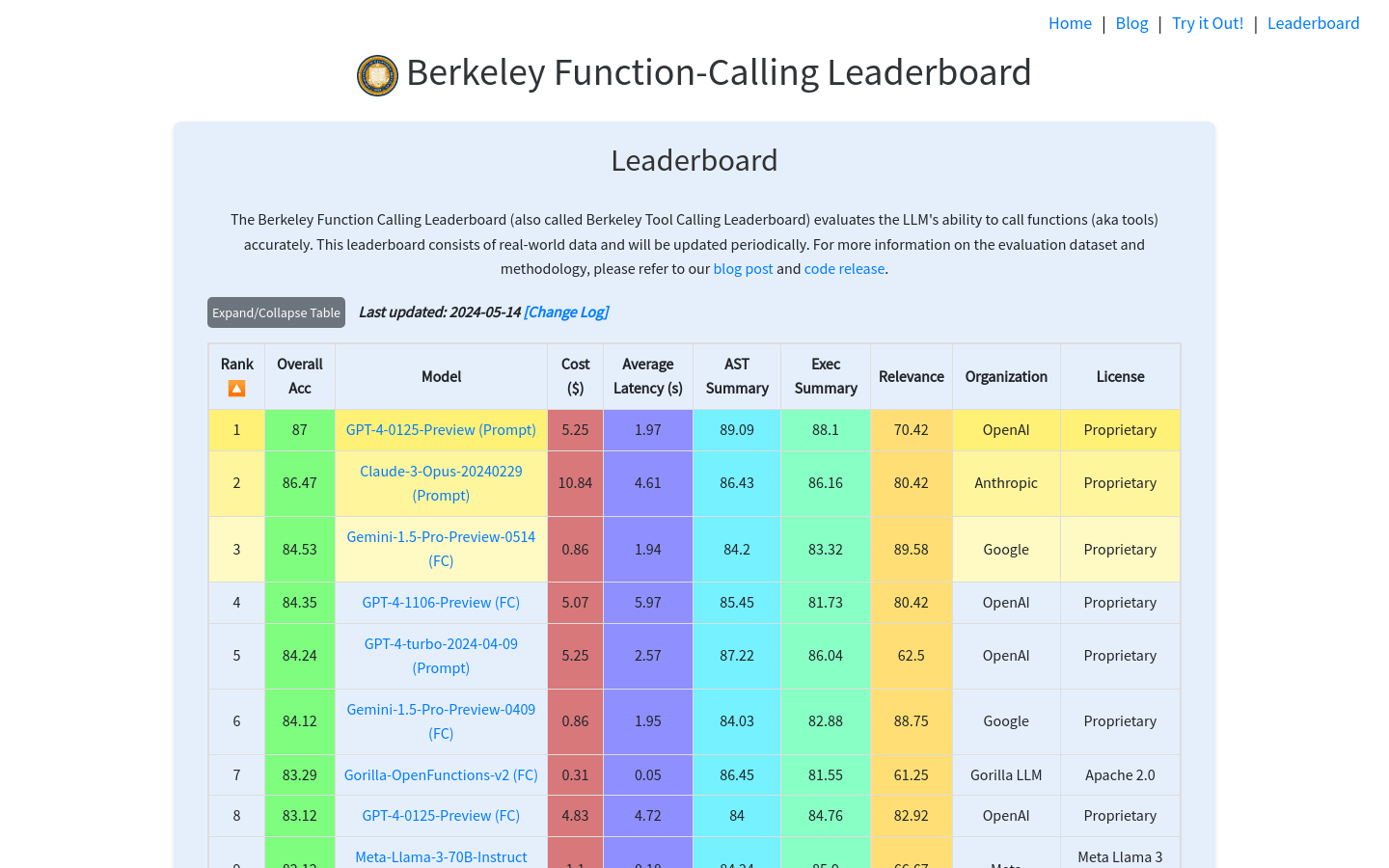
Berkeley Function-Calling Leaderboard
AI评估
编程
国外精选
Berkeley Function-Calling Leaderboard(伯克利函数调用排行榜)是一个专门用来评估大型语言模型(LLMs)准确调用函数(或工具)能力的在线平台。该排行榜基于真实世界数据,定期更新,提供了一个衡量和比较不同模型在特定编程任务上表现的基准。它对于开发者、研究人员以及对AI编程能力有兴趣的用户来说是一个宝贵的资源。
需求人群:
"该产品适合AI研究人员、开发者以及对大型语言模型编程能力有兴趣的技术人员。它可以帮助他们了解不同模型在函数调用任务上的表现,选择最适合自己项目需求的模型,并评估模型的经济性和效率。"
使用场景示例:
研究人员使用该排行榜来比较不同LLMs在特定编程任务上的表现。
开发者利用排行榜数据选择适合其应用场景的AI模型。
教育机构可能使用该平台作为教学资源,展示AI技术的最新进展。
浏览量:8
类似应用
